AMD vs英伟达:AI成决定性战场

本报记者 秦枭 北京报道
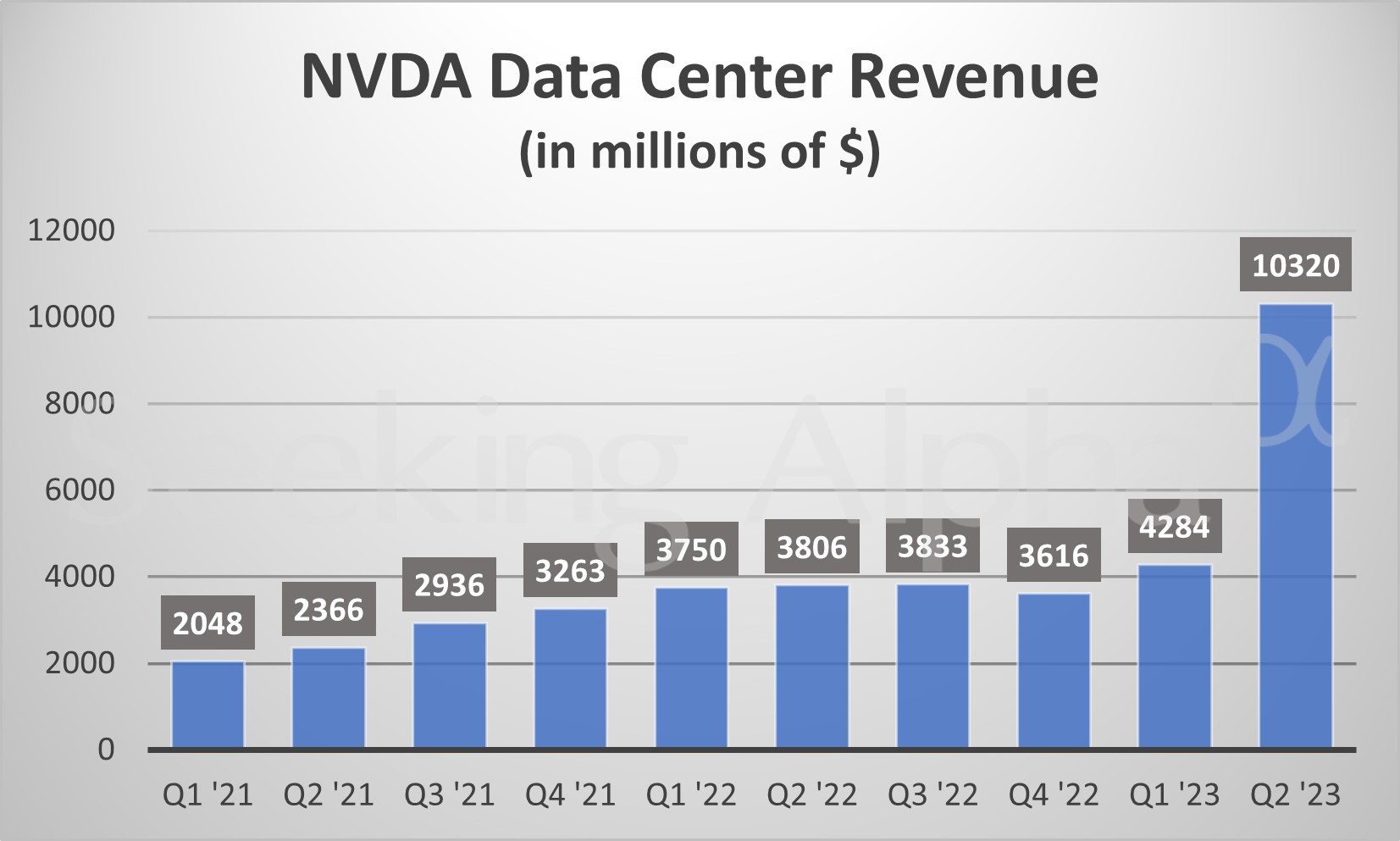
AMD与英伟达的显卡之争已经持续了20余年,双方势均力敌,交错领先。但在最近以AI大模型为战场的芯片之争中,英伟达优势尽显。据统计机构Jon Peddie Research 的数据统计报告显示,截至2022年四季度,英伟达(NVIDIA)占据了独立GPU84%的市场份额。其中,AI芯片当居首功。8月8日,英伟达再向市场展示了新一代英伟达超级AI芯片GH200。其创始人兼CEO黄仁勋说:“GH200为世界上最快的内存。”有业内人士预测,英伟达与AMD之间的差距将进一步拉大。
不过,《中国经营报》记者了解到,AMD正计划在2023年第四季度扩产其AI芯片MI300系列,并保证在2024年供应充足,以此来应对英伟达的“一家独大”, 其CEO苏姿丰预测,新芯片的发布将为其带来强劲的业绩增长,预计2023年包括MI300芯片在内的销售额将超过2022年的60.4亿美元。
英伟达强势“称雄”
“2018 年是一个‘孤注一掷’的时刻,要求我们重新发明硬件、软件、算法。而当我们用 AI 重新发明 CG(计算机图形学)时,我们也在重新发明 GPU(图形处理器)用于 AI。”黄仁勋5年前的豪赌正在迎来收获期。
ChatGPT的横空出世,让AI产业迎来“iPhone时刻”, 科技巨头争相谋局落子,继微软、谷歌之后,国内企业百度、阿里巴巴等也先后发布大模型,并进行用户测试和企业应用接入。汹涌的人工智能浪潮导致创建高级人工智能程序所需的芯片极为短缺。
为了训练ChatGPT,OpenAI构建了由近3万张英伟达V100显卡组成的庞大算力集群,GPT-4更是达到了100万亿的参数规模,其对应的算力需求同比大幅增加。TrendForce分析认为,要处理近1800亿参数的GPT-3.5大型模型,需要2万颗GPU芯片,而大模型商业化的GPT需要超过3万颗,GPT-4则需要更多。
GPU Utils 8月4日公布的一组数据显示:OpenAI 的GPT-4可能在1万到2.5万张A100 GPU芯片上进行训练;Meta拥有约21000个英伟达A100;特斯拉拥有约7000个A100;Stability AI 拥有约5000个A100;Falcon-40B模型(400亿参数)在384个A100上进行训练。根据马斯克的说法,GPT-5可能需要3万~5万张H100显卡。
即便台积电开足马力为英伟达生产,也仍存在巨大缺口。根据GPU Utils的测算,AI芯片H100在2023年8月的市场总需求可能在43.2万张左右,而目前一张H100芯片在eBay上的价格甚至炒到了4.5万美元,折合人民币超过了30万元。
凭此,英伟达今年以来的股价上涨超200%,市值突破了1万亿美元,成为全球最有价值的芯片公司。
然而,英伟达并未满足于此,开始频频推出新款GPU用来提升AI训练能力。今年3月,英伟达发布了H100 NVL GPU、L4 Tensor Core GPU、L40 GPU、NVIDIA Grace Hopper四款AI芯片,以满足生成式AI日益增长的算力需求。
在上一代还未量产上市的背景下,英伟达又在8月8日世界计算机图形学会议SIGGRAPH上,由黄仁勋发布了H100的升级版GH200。
据了解,GH200全球首发采用HBM3e高带宽内存,与英伟达目前最高端的AI芯片H100使用同样的GPU,但不同之处在于,GH200将同时配备高达141GB的内存和72核ARM中央处理器,每秒5TB带宽。和现有Grace Hopper型号相比,最新版本的GH200超级芯片能够提供3.5倍以上的内存容量和3倍以上的带宽。和H100相比,GH200超级芯片的内存增加了1.7倍,带宽增加了1.5倍。全新一代的GH200预计明年二季度开始生产。
黄仁勋表示,一台服务器可以同时装载两个GH200超级芯片,大型语言模型的推理成本将会大幅降低。按照黄仁勋的介绍,在相同的成本(1 亿美元)下,2500 块 GH200 组成的计算中心,在 AI 计算的能效上,要比传统的 CPU 计算中心高 20 倍。
东方证券研报指出,英伟达仍旧牢牢占据AI基础设施领域的主导地位。自ChatGPT引领生成式AI浪潮以来,NVIDIA GPU已成为支持生成式AI和大模型训练的大算力AI芯片首选。随着此次GH200超级AI芯片的升级以及多款GPU、服务器产品的推出,英伟达展现了在AI基础设施领域的绝对主导地位。
AMD背水一战
《福布斯》杂志评论称:“如果业界还有英伟达潜在的对手,那一定包括苏姿丰和她掌管的AMD。”
英伟达发布GH200被看做是对于近期动作频频的AMD的“反击”。在近日举行的AMD第二季度业绩说明会上,苏姿丰表示,到2027年,数据中心的人工智能加速器市场可能会超过1500亿美元。个人电脑是推动半导体处理器销量的传统产品,但随着个人电脑销量下滑,人工智能芯片成为半导体行业的新亮点之一。
与此同时,苏姿丰指出,计划在2023年第四季度扩产MI300系列芯片,包括CPU-GPU混合型MI300A和纯GPU型MI300X。相关样品已经送达客户进行测试,预计在2024年批量销售。
MI300X是一款专门面向生成式AI的加速芯片,拥有1530亿个晶体管。其HBM(高带宽存储器)容量及显存带宽,分别是英伟达H100的2.4倍及1.6倍,由于HBM容量大幅提升,单颗MI300X芯片可以运行800亿参数模型。
实际上,近几年,与英伟达类似,AMD的战略重心也在向AI转移。苏姿丰也不止一次地表明自己对于AI的态度。在今年早些时候举办的CES 2023科技大会上,苏姿丰发表了“AI is the defining megatrend in technology(AI是未来科技的决定性趋势)”的主题演讲。她说道:“AI已是AMD当前的第一战略重点,我们正积极与所有客户合作,将联合解决方案推向市场。”
除了硬件端之外,AMD在软件端也欲与英伟达试比高。其在不断加大软件生态的投入,推出了用于数据中心加速、一套完整软件栈工具AMD ROCm系统,包括为PyTorch 2.0提供即时“零日”支持,AI模型“开箱即用”等。ROCm软件栈可与模型、库、框架和工具的开放生态系统配合使用,ensorFlow和Caffe深度学习框架也已加入第五代ROCm。
不仅如此,AMD也在尝试“重启”中国市场, AMD正在认真考虑采用类似策略以将MI300和旧版MI250芯片产品出口中国。苏姿丰说道:“当然,我们的计划是完全遵守美国的出口管制。但我们确实相信有机会为我们正在寻找人工智能解决方案的中国客户开发产品,我们将继续朝着这个方向努力。”
即便如此,在半导体分析师王志伟看来,在AI芯片领域,英伟达的地位不可撼动。其成熟的芯片已经得到市场认可,并被广泛使用,而AMD相关产品仍处量产初期,其效果也需要长时间的市场验证。
值得注意的是,AMD执行副总裁Forrest Norrod此前曾坦承,英伟达在GPU运算加速卡方面建构了丰富的软件生态系统,几乎覆盖了多数市场需求,其护城河之深,让AMD如今不可能来得及复制英伟达走过的这条路,需另辟蹊径。
[免责声明]本文来源于网络,不代表本站立场,如转载内容涉及版权等问题,请联系邮箱:83115484@qq.com,我们会予以删除相关文章,保证您的权利。转载请注明出处:http://www.ukzlpcl.cn/post/15869.html